模式识别复习总结
# 前情提要:
本篇只适合与考试复习用,并不深入讲解每个算法的具体内容,详细知识点请移步本分类的其他文章
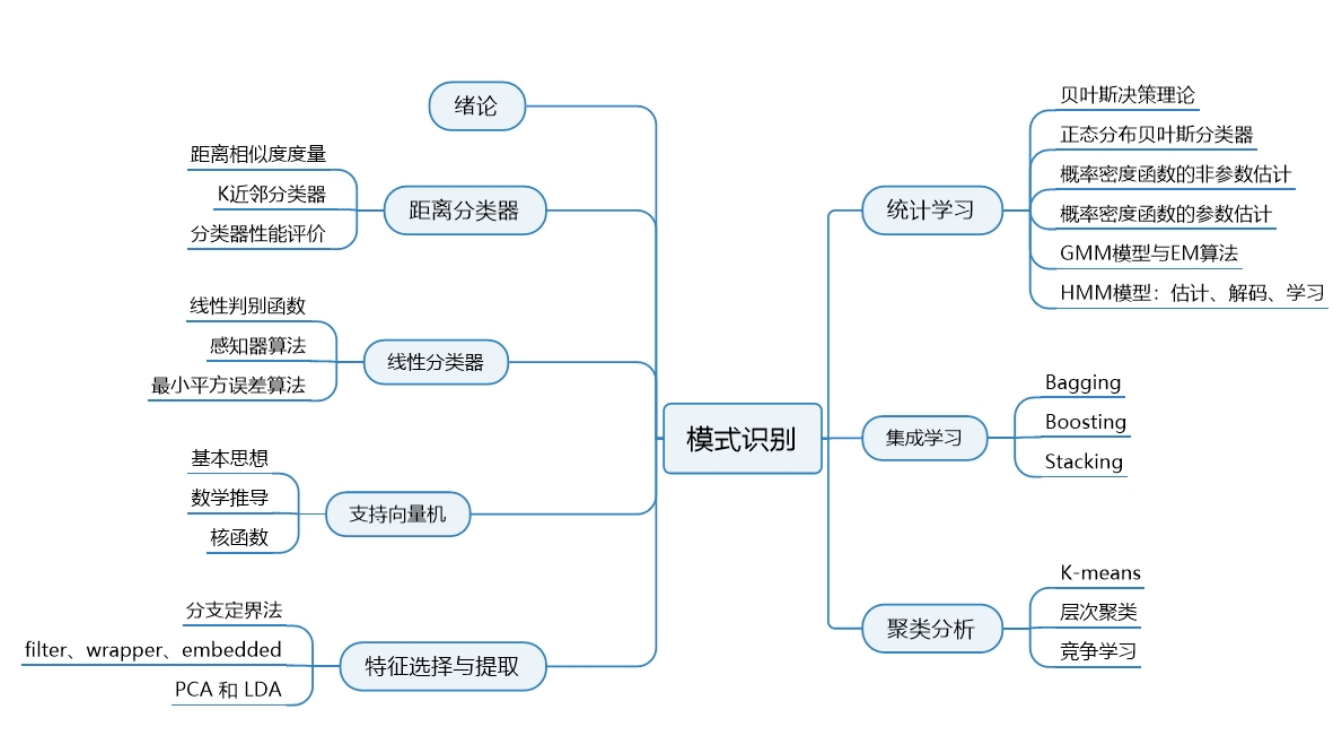
# 一、距离分类器
模板匹配
是向量 和平均值 的距离
最近邻分类器
- 计算每个类别训练样本的均值作为匹配模板
K - 近邻分类器
距离和相似度度量:
什么样的函数可以作为距离度量
- 非负性、对称性、自反性、三角不等式
常用函数
- :\sqrt
- :
- :
相似性度量
角度相似性:
相关系数:
特征归一化、标准化
均匀缩放:
高斯缩放:
缩放的理由:使样本每一维特征都分布在相同或相似的范围内,计算距离度量时每一维特征上的差异都会得到相同的体现
分类器性能评价:
常用评价指标
准确率:
错误率:
查准率:
查全率 (召回率):
真实类别 \ 预测结果 正例 反例 正例 TP (真正例) FN (假反例) 反例 FP (假正例) TN (真反例)
常用评价方法:
- 留出法 (hold-out)
- 交叉验证法 (cross validation)
- 自助法 (bootstrap)
偏差 (Bias) 和方差 (Variance)
过拟合与欠拟合 (Over- and Under-Fitting)
如何解决欠拟合:
1、增加模型复杂数学公式度,即选择更复杂数学公式的模型
2、特征工程,即选择更好的有助于模型预测的特征
3、调整超参数
如何解决过拟合:
1、增加训练数据量
2、降低模型复杂数学公式度
3、通过正则化的方法,限制模型参数大小
4、数据增强,通过对训练数据旋转、翻转,增加样本多样性
# 二、线性判别函数
线性判别函数:
线性判别函数的几何意义
- 分类超平面 将空间分成属于不同类别的两部分 和
- 权矢量 垂直与分类面,指向 的区域
- 坐标原点到分类界面 的距离:
线性判别函数的增广形式:
增广权矢量:
样本规范化:
统一形式:
优化方法 - 梯度下降法:
感知器算法:
最小平方误差算法:
伪逆法:( 可能为奇异阵,且计算量巨大)
迭代求解法:
多类别线性分类:
- 方法:一对多、一对一
- 判别准则:
- 若存在,使得,则判别 属于 类
- 如果对任意,有,则判别 属于 类
支持向量机:
权矢量:
偏置:可以用支持向量满足的条件求得
软间隔:
特征选择与特征提取:
什么是维数诅咒:当数学空间维度增加时,体积指数级增加的难题
主成分分析 (PCA)
Input: 样本集;
Output: 降维样本集\{y_1,...,y_2\},y_i\in R^
1: 计算样本集 的均值 和协方差矩阵;
2: 计算矩阵 的特征值,并从大到小排序;
3: 选择前 个特征值对应矢量作为列矢量,构造变换矩阵;
4: 计算降维样本集:
线性判别分析:
- 准则:
PCA vs LDA:
- PCA: 无监督的成分分析方法,只考虑了样本集的整体分布,没有使用样本的类别信息
- LDA: 有监督的成分分析方法,根据 Fisher 准则寻找可分性最大意义的最优线性映射,充分保留样本的类别可分性信息
# 三、贝叶斯决策理论
基于最小错误率的贝叶斯决策:
- 最大后验概率:
基于最小风险的贝叶斯决策
- 将 判为 类的平均风险:
- 最小平均风险准则:
正态分布的贝叶斯分类器:
假设每个类别的类条件概率密度函数 都满足正态分布
最小错误率贝叶斯函数的对数表示:
情况一: 距离分类器
情况二: 线性分类器
情况三: 任意 二次判别函数
朴素贝叶斯分类器:
协方差矩阵难以估计
假设样本的各位特征相互独立
# 三、非参数估计和参数估计
非参数估计 vs 参数估计:
- 非参数估计不需要任何关于分布的先验知识,适用性好;参数估计方法需要关于分布形式的先验知识,估计的准确程度依赖于先验知识是否准确
- 非参数估计能取得的准确的估计结果,需要的训练样本数量远多于参数估计;参数估计由于有先验知识的存在,参数估计方法使用比较少的训练数据就可以得到较好的估计结果
非参数估计:
Parzen 窗法:区域体积 是总样本数 的函数,如:
窗函数条件:
- 满足以下函数:
- 最常使用窗函数 Gauss 函数:
判断样本 是否在超立方体 内:
超立方体内的样本数:
概率密度函数的估计:
Input: 训练集,窗函数,窗函数宽度
Output: 待识别模式 所属类别
1: 保存每个类别的训练样本集;
2:for to do
3: 计算 类的概率密度函数值:
K - 临近法:落在区域内的样本数 是总样本数 的函数,如:k_n=\sqrt
- Input: 训练集,参数
- Output: 待识别模式 所属类别
- 1:计算待识别模式与每个训练样本的距离:
- 2:选择距离最小的前 个样本,统计其中包括各个类别的样本数;
- 3:return
参数估计:
最大似然估计:
- 对数似然函数:
- 求解优化问题:
- 一维正态分布的最大似然估计:,
- 多维正态分布的最大似然估计:,
# 四、高斯混合模型
GMM 可以看作是一种 "通用" 的概率密度函数
GMM 的最大似然估计
- EM 算法
- 初始化参数
- 根据参数估计隐变量的概率
- 根据隐变量的概率,最大化模型的参数
- 迭代直到满足收敛精度
- EM 算法
举例:硬币 A 和 B,抛出正面的概率 和 未知
使用 EM 算法进行求解:
假设抛出正面的概率
步:
5 0.45 0.55 2.2 2.2 2.8 2.8 9 0.8 0.2 7.2 0.8 1.8 0.2 8 0.73 0.27 5.9 1.5 2.1 0.5 4 0.35 0.65 1.4 2.1 2.6 3.9 7 0.65 0.35 4.5 1.9 2.5 1.1 21.3 8.6 11.7 8.4 以此类推
K-Means 聚类方法
Input: 数据集,聚类数
Output: 数据集的聚类标签D_Y=\
1、随机初始化聚类中心\
2、repeat
3、 更新聚类标签:
4、 更新聚类中心:
5、until 不再改变
# 五、隐马尔可夫
- 在时刻 由隐状态 输出观察值v(t)\in\
- 经过 个时刻后,可以观察到 HMM 输出一个观察序列
隐马尔可夫模型:
模型参数:
根据参数绘制模型
估值问题:
已知 HMM 模型参数,计算模型输出特定观察序列 的概率
举例:
,
分别对应
解码问题:
已知 HMM 模型参数,计算最有可能的特定观察序列 的隐状态转移序列
举例:
,
分别对应
保存两个回溯数组,\phi_
可以看到由 转过来的概率更大,因此
;
可以看到由 转过来的概率更大,因此
经过比较,从 转过来的概率更大,因此
经过比较,从 转过来的概率更大,因此
经过比较,从 转移过来的概率更大,因此
经过比较得到,从 转移过来的概率更大,因此
经过最后计算,最后一天时, 的概率为, 的概率为
因此
开始回溯,最后一天是,所以从 回溯,找到的是,
继续回溯,也是从 找,找到,
继续回溯,这次从 找,找到,
因此最后的答案就是
学习问题
- 算法(了解就行,出题的话计算量过大,多半不会考)
# 六、集成学习、聚类分析(除了红色标记,其他可以只做了解)
无监督学习:
在不知道训练样本的标记信息时,揭示训练数据的内在性质和规律
无监督学习中,训练样本的标记信息时未知的
学习的目标是要揭示训练数据的内在性质和规律
有监督学习与无监督学习区别 [.red]:
- 有监督学习有标签,无监督学习无标签,有监督学习是为了在训练集中找到规律,然后对测试数据集运用这种规律,达到分类的效果,而无监督学习寻找数据集中的规律性不一定要达到划分数据集的目的。
无监督学习的作用和应用:
- 揭示训练数据的内在性质和规律
- 应用:降维算法 (如 PCA),聚类算法 (如 K-Means),异常检测算法
聚类:
- K-means
- 普通 K-means 算法
- 模糊 K 均值聚类
- 层次聚类
- AGNES 算法
- 聚类数的选择
- Dunn 指数:"最小聚类间距" 除以 "最大聚类直径"
- 聚类间距:聚类之间最近一对样本的距离
- 聚类直径:类内距离最远的两个样本之间的距离
- Davies-Bouldin 指数:每个聚类与其他聚类之间的最大相似度的均值
- 类内离散度:聚类均值之间的距离
- 类内离散度:样本到聚类均值的均方距离度量
- 类内相似度:类内离散度之和 / 类间离散度
- Dunn 指数:"最小聚类间距" 除以 "最大聚类直径"
竞争学习
- 竞争网络学习算法
- SOFM 学习算法
集成学习:
Bagging:
自助法(Bootstrapping)
- 从数据集 中有放回地随机抽样 个样本,构成训练集
- 从数据集 中有放回地随机抽样 个样本,构成训练集
- 重复若干次,计算平均的评估结果
通常来说,集成学习具有相似的偏差,但方差更低
Random-Forrest
Boosting
- AdaBoost
- 学习 个基分类器,加权线性组合
- 基分类器的权重 是算法学习得到的参数
- 样本集的加权重采样
- AdaBoost
Stacking
可以将训练集分为两份,一份用来训练一级分类器,训练出来的一级分类器在另一份数据上进行预测,预测结果来训练元分类器
更健壮的方法:k - 折交叉验证,k-1 折用来训练一级分类器,另一折产生分类器的预测