# 手写数字识别
# 一、前置库
import numpy as np
import matplotlib.pyplot as plt
import os
from array import array as pyarray
import struct
from sklearn.metrics import accuracy_score,classification_report
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 二、数据集
数据集采用的从官网上下载的 mnist 数据集,下载地址为 http://yann.lecun.com/exdb/mnist/
一共包含了 4 个部分
1、训练数据集: (9.45 MB,包含 60,000 个样本)
2、训练数据集标签:(28.2 KB,包含 60,000 个标签)
3、测试数据集:(1.57 MB ,包含 10,000 个样本)
4、测试数据集标签:(4.43 KB,包含 10,000 个样本的标签)
可以看到这些数据集和以往的数据集不太一样,需要一些特殊的方法才可以将它们读出来,处理代码如下:
def load_mnist(image_file,label_file,path="F:/Mechine Learning/Handy Writing/mnist"): | |
digits = np.arange(10) | |
fname_image = os.path.join(path,image_file) | |
fname_label = os.path.join(path,label_file) | |
flbl = open(fname_label,'rb') | |
magic_nr,size = struct.unpack(">II",flbl.read(8)) | |
lbl = pyarray("b",flbl.read()) | |
flbl.close() | |
fimg = open(fname_image,'rb') | |
magic_nr,size,rows,cols = struct.unpack(">IIII",fimg.read(16)) | |
img = pyarray("B",fimg.read()) | |
fimg.close() | |
ind = [k for k in range(size) if lbl[k] in digits ] | |
N = len(ind) | |
images = np.zeros((N,rows*cols),dtype=np.uint8) | |
labels = np.zeros((N,1),dtype=np.uint8) | |
for i in range(len(ind)): | |
images[i] = np.array(img[ ind[i]*rows*cols : (ind[i]+1)*rows*cols]).reshape((1,rows*cols)) | |
labels[i] = lbl[ind[i]] | |
return images,labels | |
train_image,train_label = load_mnist("train-images.idx3-ubyte","train-labels.idx1-ubyte") | |
test_image,test_label = load_mnist("t10k-images.idx3-ubyte","t10k-labels.idx1-ubyte") |
这样所有数据被读进来了,下面看看部分图片
def show_image(imgdata,imgtarget,show_column,show_row): | |
for index,(im,it) in enumerate(list(zip(imgdata,imgtarget))): | |
xx = im.reshape(28,28) | |
plt.subplots_adjust(left=1,bottom=None,right=3,top=2,wspace=None,hspace=None) | |
plt.subplot(show_row,show_column,index+1) | |
plt.axis('off') | |
plt.imshow(xx,cmap='gray',interpolation='nearest') | |
plt.title('label:%i'%it) | |
show_image(train_image[:50],train_label[:50],10,5) |
显示如下:

对数据再进行一些处理,进行归一化
train_image = [im/255.0 for im in train_image] | |
test_image = [im/255.0 for im in test_image] |
接下来用不同的方法进行分类,大部分模型都是用的 里的
# 一、KNeighbors
from sklearn.metrics import accuracy_score,classification_report | |
from sklearn.neighbors import KNeighborsClassifier | |
knc = KNeighborsClassifier(n_neighbors=10) | |
knc.fit(train_image,train_label.ravel()) | |
predict = knc.predict(test_image)\ | |
print("accuracy_score:%.4lf" % accuracy_score(predict,test_label)) | |
print("Classification report for classifier %s:\n%s\n" % (knc,classification_report(test_label,predict))) |
结果如下:
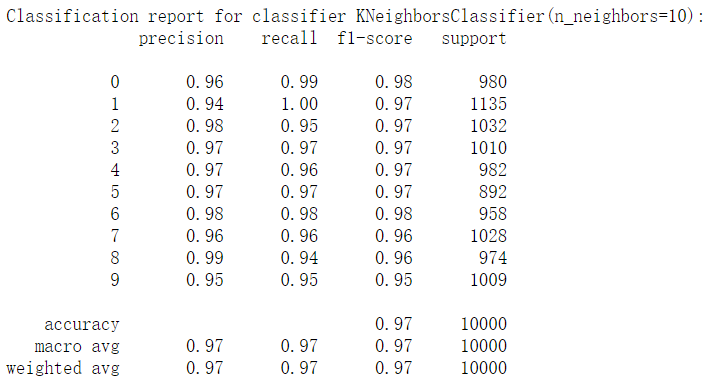
准确率为:
# 二、MultinomialNB
from sklearn.naive_bayes import MultinomialNB | |
mnb = MultinomialNB() | |
mnb.fit(train_image,train_label.ravel()) | |
predict1 = mnb.predict(test_image) | |
print("accuracy_score:%.4lf" % accuracy_score(predict1,test_label)) | |
print("Classification report for classifier %s:\n%s\n" % (mnb, classification_report(test_label, predict1))) |
结果如下:
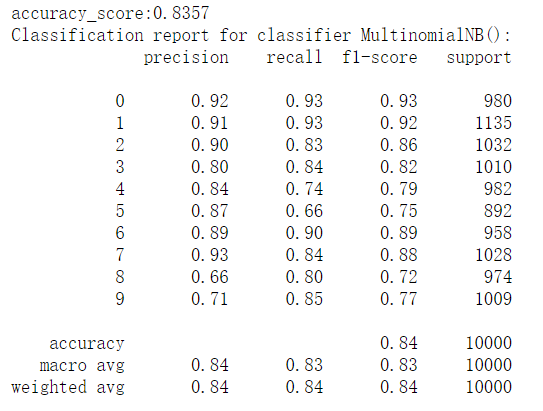
# 三、决策树
from sklearn.tree import DecisionTreeClassifier | |
dtc = DecisionTreeClassifier() | |
dtc.fit(train_image,train_label.ravel()) | |
predict2 = dtc.predict(test_image) | |
print("accuracy_score:%.4lf" % accuracy_score(predict2,test_label)) | |
print("Classification report for classifier %s:\n%s\n" % (dtc, classification_report(test_label, predict2))) |
结果如下:
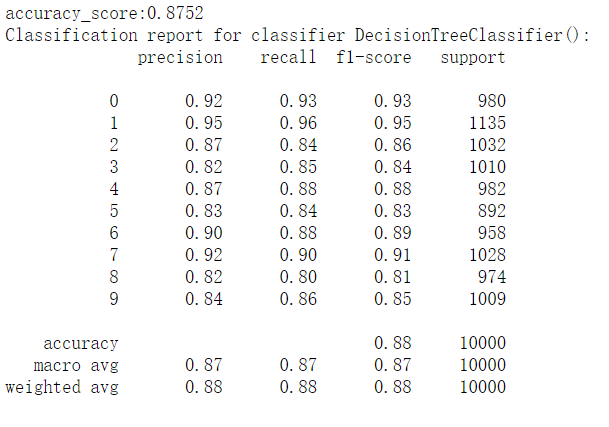
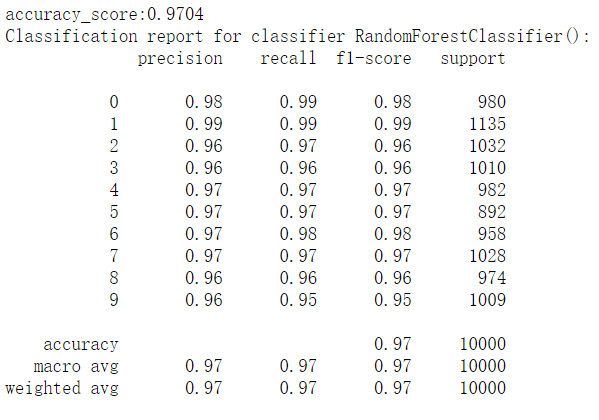
# 四、随机森林
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(train_image,train_label.ravel())
predict3 = rfc.predict(test_image)
print("accuracy_score:%.4lf" % accuracy_score(predict3,test_label))
print("Classification report for classifier %s:\n%s\n" % (rfc, classification_report(test_label, predict3)))
结果如下:
# 五、逻辑回归
from sklearn.linear_model import LogisticRegression | |
lr = LogisticRegression() | |
lr.fit(train_image,train_label.ravel()) | |
predict4 = lr.predict(test_image) | |
print("accuracy_score: %.4lf" % accuracy_score(predict4,test_label)) | |
print("Classification report for classifier %s:\n%s\n" % (lr, classification_report(test_label, predict4))) |
结果如下:

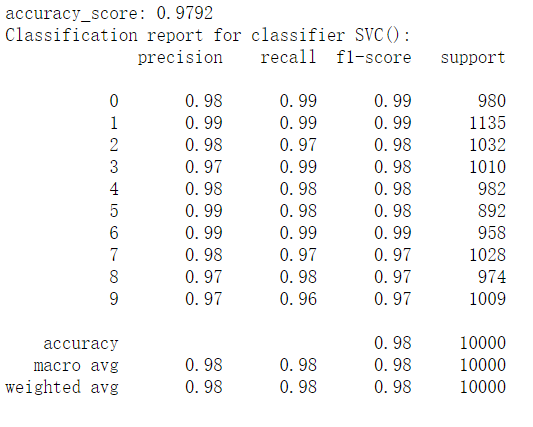
# 六、SVM
from sklearn.svm import SVC | |
svc = SVC() | |
svc.fit(train_image,train_label.ravel()) | |
predict5 = svc.predict(test_image) | |
print("accuracy_score: %.4lf" % accuracy_score(predict5,test_label)) | |
print("Classification report for classifier %s:\n%s\n" % (svc, classification_report(test_label, predict5))) |
结果如下: