# 机器学习的第一篇文章,第一次从零开始尝试用决策树预测模型
先不得不吐槽一下这门课程的设置,讲课很抽象,全是理论,没有代码,讲完理论直接实践,很是让我无语,上完课给我一种我好想什么都没学的错觉(emmm, 也可能是真的)
吐槽一下感觉舒服多了,开始写点实际的
先看看各个数据集吧
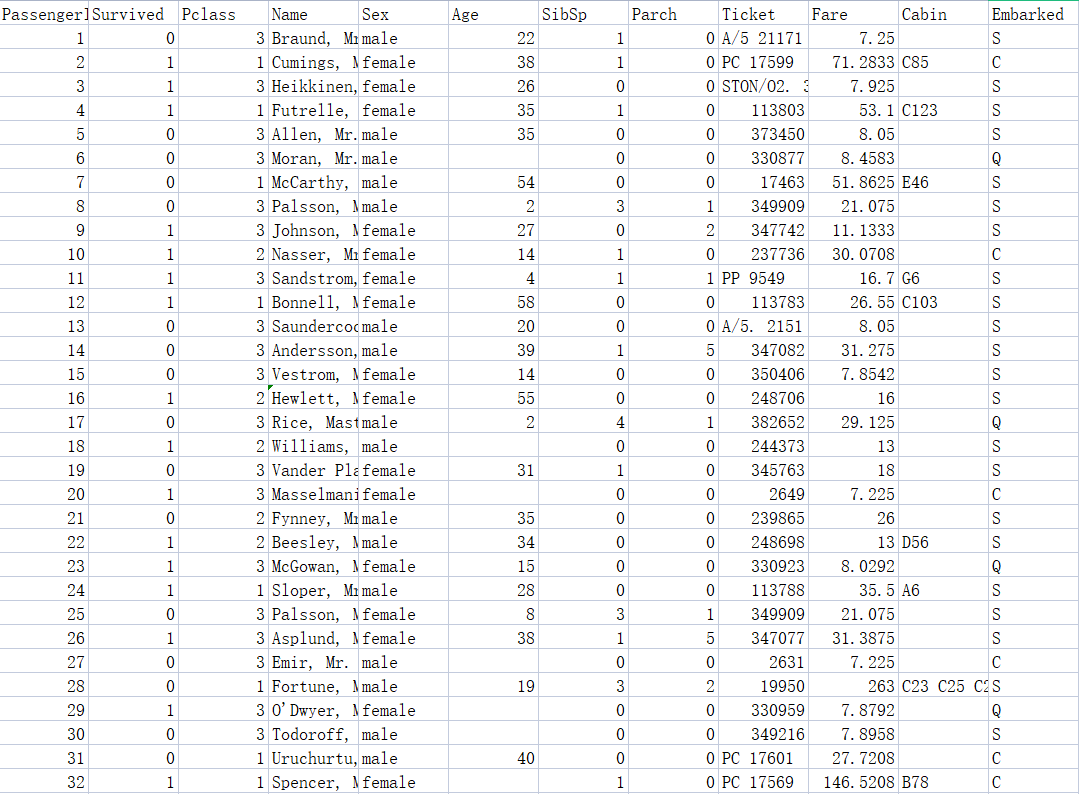
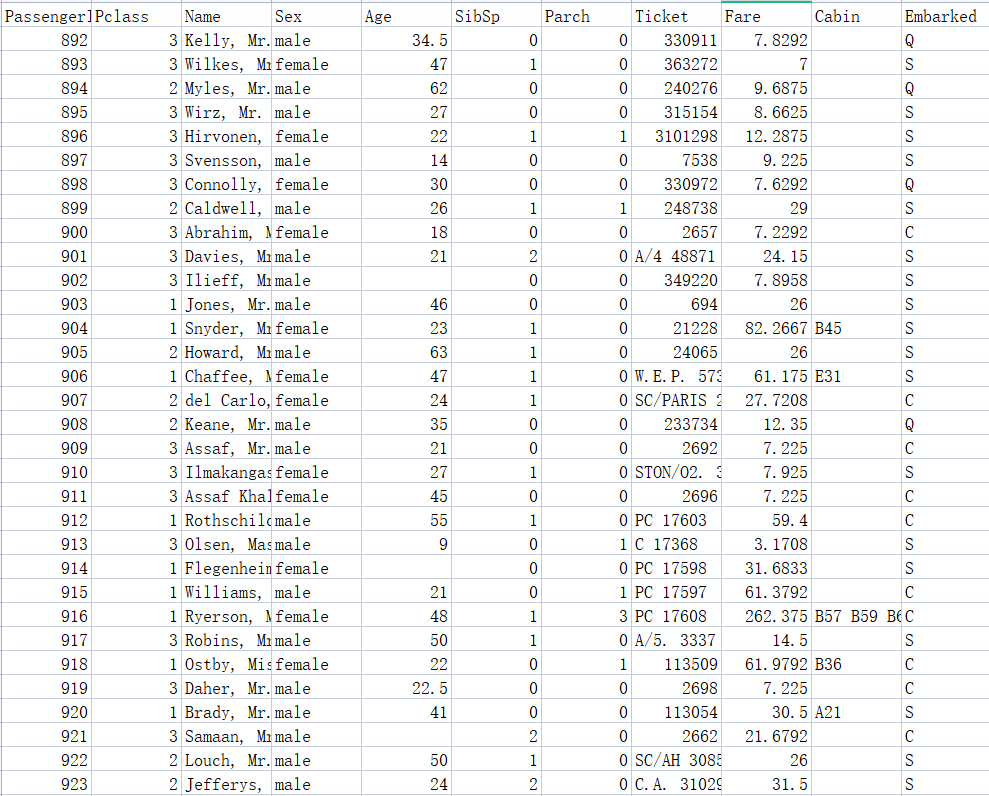
很经典的沉船数据集,接下来要用决策树来模拟预测
先进行数据处理
一般实际的数据很少没有缺失值的,所以要考虑把缺失值补上;
决策树训练需要特征值,也就是将特征值处理出来,有些字段不仅很难处理成特征值而且即使处理后也对训练模型没有多大帮助;
决策树的特征值只能是小数或者是整数,因此字符串的特征值需要进行映射处理
以上面数据为例:
<font size="4">
- Name 这个特征很杂很散,而且是字符串,很难映射成数值,因此抛弃掉。 <br/>
- Sex 这个特征值虽然是字符串,但只有两种,很好映射,因此保留并映射成 0 和 1。<br/>
- Age 这个特征值很明显有空缺,然后根据大佬推荐用其他 Age 的平均值补上空缺。 <br/>
- SibSp 和 Parch 这两个特征值只有数字,直接取出保留。 <br/>
- Ticket 问题和 Name 一样,抛弃。 <br/>
- Fare 均为小数,但是也有缺失值的问题,采用均值补上 <br/>
- Cabin 数据缺失值很多,而且也是字符串型的特征值,舍弃 <br/>
- Embarked 只有 C,S,Q 三种字符,可以映射后当做特征值,保留 <br/>
</font>
这是初步的想法,在 上看了一下别人的数据处理方式,深有体会,别人的处理方法可以保留更多信息,下面是他们的处理方法
<font size="4">
- Name 这个特征虽然很复杂,但是英文名往往会有头衔,如 Mr、Mrs、Master 等,可以抽象出来成一个特征。 <br/>
- Sex 这个特征值虽然是字符串,但只有两种,很好映射,因此保留并映射成 0 和 1。<br/>
- Age 这个特征值很明显有空缺,用平均值补全。 <br/>
- SibSp 和 Parch 这两个特征值只有数字,将这两个特征值加起来成为一个 FamilySize 特征,再根据这个 FamilySize 特征可以抽取出 IsAlone 特征,也就是如果 FamilySize 是 1 的话就是独身一人,IsAlone 为 1。 <br/>
- Ticket 确实没办法处理,抛弃掉。 <br/>
- Fare 均为小数,但是也有缺失值的问题,采用均值补上 <br/>
- Cabin 数据缺失值很多,但我们可以抽取出 HasCabin 特征,如果有,则为 1,否则为 0 <br/>
- Embarked 只有 C,S,Q 三种字符,可以映射后当做特征值,保留 <br/>
</font>
还有一点就是上面的测试集答案即 是用来提示你输出格式的,不代表真正答案,因此剪枝的时候,我们从训练集,也就是 分割出一部分用来后剪枝
下面用决策树解决这个问题,分两种写法,一种是用 库来解决的,很简便,正确率很高,一种是我自己手模的决策树解决的,很长,正确率不高
# 一、sklearn 库解决
Python 处理数据代码段如下:
def load_data(): | |
train=pd.read_csv('F:/机器学习/titanic/train.csv') | |
test=pd.read_csv('F:/机器学习/titanic/test.csv') | |
true=pd.read_csv('F:/机器学习/titanic/gender_submission.csv') | |
# 处理数据 | |
x_train=train[['Pclass','Sex','Age']] | |
y_train=train['Survived'] | |
x_test = test[['Pclass', 'Sex', 'Age']] | |
y_true=true['Survived'] | |
# 填补缺失值 | |
x_train['Age'].fillna(x_train['Age'].mean(),inplace=True) | |
x_test['Age'].fillna(x_test['Age'].mean(), inplace=True) | |
# 字典处理 | |
dict=DictVectorizer(sparse=False) | |
X_train=dict.fit_transform(x_train.to_dict(orient='record')) | |
X_test=dict.transform(x_test.to_dict(orient='record')) | |
return X_train,X_test,y_train,y_true |
处理完了数据,就可以开始训练模型了
from sklearn import tree | |
from sklearn.metrics import f1_score, accuracy_score, plot_confusion_matrix | |
X_train,X_test,Y_train,Y_test = load_data() | |
clf = tree.DecisionTreeClassifier(random_state=2021,max_depth=5) | |
clf = clf.fit(X_train,Y_train) |
然后写一个评价函数来看看预测正确率是多少
def eval(clf,X_train, X_test, y_train, y_test): | |
predicted = clf.predict(X_train) # 模型预测 | |
accuracy = accuracy_score(y_train, predicted) | |
print("训练集准确率", accuracy) | |
f1 = f1_score(y_train, predicted,average='macro') | |
print("训练集f1_score", f1) | |
predicted = clf.predict(X_test) | |
accuracy = accuracy_score(y_test, predicted) | |
print("测试集准确率", accuracy) | |
f1 = f1_score(y_test, predicted,average='macro') | |
print("测试集f1_score", f1) | |
plot_confusion_matrix(clf, X_test, y_test,cmap="GnBu") |
执行函数
eval(clf,X_train, X_test, Y_train, Y_test) |
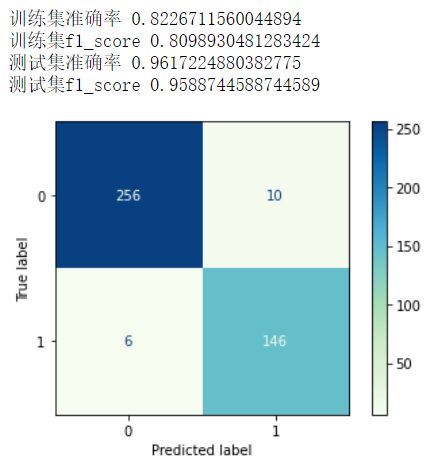
可以看到准确率很高,很好,很强大。
最后把决策树的树形画出来:
from sklearn.tree import DecisionTreeClassifier,export_graphviz | |
import graphviz | |
from graphviz import Digraph | |
dot_data = tree.export_graphviz(clf, out_file=None) | |
graph = graphviz.Source(dot_data) | |
graph.render("F:/机器学习/demo") |
<a href="https://raw.githubusercontent.com/ntmydb/blog_profile/main/demo.pdf" target="_blank" >demo.pdf</a><br/>
# 二、手模决策树解决
# 1、前置使用库
from math import log,inf | |
import operator | |
import numpy as np | |
import pandas as pd | |
import copy |
# 2、数据集处理
def get_title(name): | |
title_search = re.search('([A-Za-z]+)\.',name) | |
if title_search: | |
return title_search.group(1) | |
return "" | |
def load_data(): | |
train=pd.read_csv('F:/机器学习/titanic/train.csv') | |
test=pd.read_csv('F:/机器学习/titanic/test.csv') | |
true=pd.read_csv('F:/机器学习/titanic/gender_submission.csv') | |
train_y = train['Survived'] | |
train.drop(["PassengerId","Ticket","Survived"],axis=1,inplace=True) | |
test.drop(["PassengerId","Ticket"],axis=1,inplace=True) | |
train["Title"]=train["Name"].apply(get_title) | |
train["Title"]=train["Title"].replace(['Lady','Countess','Capt','Col','Don','Dr','Major','Rev','Sir','Jonkheer','Dona'],'Rare') | |
train["Title"]=train["Title"].replace('Mlle','Miss') | |
train["Title"]=train["Title"].replace('Ms','Miss') | |
train["Title"]=train["Title"].replace('Mme','Mrs') | |
test["Title"]=test["Name"].apply(get_title) | |
test["Title"]=test["Title"].replace(['Lady','Countess','Capt','Col','Don','Dr','Major','Rev','Sir','Jonkheer','Dona'],'Rare') | |
test["Title"]=test["Title"].replace('Mlle','Miss') | |
test["Title"]=test["Title"].replace('Ms','Miss') | |
test["Title"]=test["Title"].replace('Mme','Mrs') | |
title_mapping = {"Mr":1,"Master":2,"Mrs":3,"Miss":4,"Rare":5} | |
train["Title"]=train["Title"].map(title_mapping) | |
train["Title"]=train["Title"].fillna(0) | |
test["Title"]=test["Title"].map(title_mapping) | |
test["Title"]=test["Title"].fillna(0) | |
train.drop(["Name"],axis=1,inplace=True) | |
test.drop(["Name"],axis=1,inplace=True) | |
train["Sex"]=(train.Sex == "female").astype("int") | |
test["Sex"]=(test.Sex == "female").astype("int") | |
train["HasCabin"] = train["Cabin"].apply(lambda x:0 if type(x) == float else 1) | |
test["HasCabin"] = train["Cabin"].apply(lambda x:0 if type(x) == float else 1) | |
train["FamilySize"] = train["SibSp"] + train["Parch"] + 1 | |
test["FamilySize"] = test["SibSp"] + test["Parch"] + 1 | |
train["IsAlone"]=(train.FamilySize==1).astype("int") | |
test["IsAlone"]=(train.FamilySize==1).astype("int") | |
train.drop(["SibSp","Parch","Cabin"],axis=1,inplace=True) | |
test.drop(["SibSp","Parch","Cabin"],axis=1,inplace=True) | |
test_y = true['Survived'] | |
dict1 = {"S":0,"C":1,"Q":2} | |
train.Embarked = train.Embarked.map(dict1) | |
test.Embarked = test.Embarked.map(dict1) | |
train.Age = train.Age.fillna(train.Age.mean()) | |
test.Age = test.Age.fillna(test.Age.mean()) | |
train.Embarked = train.Embarked.fillna(train.Embarked.median()) | |
test.Embarked = test.Embarked.fillna(test.Embarked.median()) | |
X_train,X_test,Y_train,Y_test = train_test_split(train,train_y,test_size=0.3,random_state = 666) | |
train_dataset = [] | |
test_dataset = [] | |
temp = [] | |
temp1 = [] | |
true_test = [] | |
labels = [x for x in train] | |
for i in X_train: | |
one_case = [] | |
for j in X_train[i]: | |
one_case.append(j) | |
temp.append(one_case) | |
for i in Y_train: | |
temp1.append(i) | |
for i in range(len(temp[0])): | |
one_case = [] | |
for j in range(len(labels)): | |
one_case.append(temp[j][i]) | |
one_case.append(temp1[i]) | |
train_dataset.append(one_case) | |
temp = [] | |
temp1 = [] | |
for i in X_test: | |
one_case = [] | |
for j in X_test[i]: | |
one_case.append(j) | |
temp.append(one_case) | |
for i in Y_test: | |
temp1.append(i) | |
for i in range(len(temp[0])): | |
one_case = [] | |
for j in range(len(labels)): | |
one_case.append(temp[j][i]) | |
one_case.append(temp1[i]) | |
test_dataset.append(one_case) | |
true_test = [] | |
for i in range(len(test[labels[0]])): | |
one_case = [] | |
for j in labels: | |
one_case.append(test[j][i]) | |
one_case.append(test_y[i]) | |
true_test.append(one_case) | |
return labels,train_dataset,test_dataset,true_test,test_y |
最后处理出来的 是训练集的各种标签, 是训练集, 是用来后剪枝的训练集, 是真正的测试集, 是 的答案
# 3、决策树具体实现代码
def calcShannonEnt(dataSet): # 计算香农熵 | |
numEntries = len(dataSet) | |
labelCounts = {} | |
for featVec in dataSet: | |
currentLabel = featVec[-1] # 取出标签 | |
if currentLabel not in labelCounts.keys(): | |
labelCounts[currentLabel] = 0 | |
labelCounts[currentLabel] += 1 # 统计出现次数 | |
shannonEnt = 0.0 | |
for key in labelCounts: | |
prob = float(labelCounts[key])/numEntries | |
shannonEnt = shannonEnt - prob*log(prob,2) | |
return shannonEnt | |
def splitDataSet(dataSet,axis,value): # 这部分是处理离散值的分割数据集 | |
retDataSet = [] | |
featVec = [] | |
for featVec in dataSet: | |
if featVec[axis] == value: | |
reducedFeatVec = featVec[:axis] | |
reducedFeatVec.extend(featVec[axis + 1:]) | |
retDataSet.append(reducedFeatVec) | |
return retDataSet | |
def splitDataSet_c(dataSet,axis,value,LorR='L'): # 这部分是处理连续值的分割数据集 | |
retDataSet = [] | |
if LorR == 'L': | |
for featVec in dataSet: | |
if float(featVec[axis]) < value: # value 是为了分割数据集选定的一个数 | |
retDataSet.append(featVec) | |
else: | |
for featVec in dataSet: | |
if float(featVec[axis]) > value: | |
retDataSet.append(featVec) | |
return retDataSet | |
def chooseBestFeatureToSplit(dataSet,labelProperty): | |
numFeatures = len(dataSet[0]) - 1 | |
baseEntropy = calcShannonEnt(dataSet) | |
bestInfoGain = 0.0 | |
bestFeature = -1 | |
bestPartValue = None | |
for i in range(numFeatures): | |
featList = [example[i] for example in dataSet] # 取出一个特征集 | |
uniqueVals = set(featList) # 去重 | |
newEntropy = 0.0 | |
bestPartValuei = None | |
if labelProperty[i] == 0: #离散值 | |
for value in uniqueVals: | |
subDataSet = splitDataSet(dataSet,i,value) | |
prob = len(subDataSet)/float(len(dataSet)) | |
newEntropy += prob * calcShannonEnt(subDataSet) | |
else: | |
sortedUniqueVals = list(uniqueVals) | |
sortedUniqueVals.sort() # 需要排序后方便选取分割值 | |
minEntropy = inf | |
for j in range(len(sortedUniqueVals) - 1): | |
partValue = (float(sortedUniqueVals[j]) + float(sortedUniqueVals[j + 1]))/2 # 分割值取两个数的平均值 | |
dataSetLeft = splitDataSet_c(dataSet,i,partValue,'L') # 分割左右数据集 | |
dataSetRight = splitDataSet_c(dataSet,i,partValue,'R') | |
probLeft = len(dataSetLeft)/float(len(dataSet)) | |
probRight = len(dataSetRight)/float(len(dataSet)) | |
Entropy = probLeft*calcShannonEnt(dataSetLeft) + probRight*calcShannonEnt(dataSetRight) | |
if Entropy < minEntropy: | |
minEntropy = Entropy | |
bestPartValuei = partValue | |
newEntropy = minEntropy | |
infoGain = baseEntropy - newEntropy | |
if infoGain > bestInfoGain: | |
bestInfoGain = infoGain | |
bestFeature = i | |
bestPartValue = bestPartValuei | |
return bestFeature,bestPartValue | |
def majorityCnt(classList): | |
classCount = {} | |
for vote in classList: | |
if vote not in classCount.keys(): # 统计出现次数 | |
classCount[vote] = 0 | |
classCount[vote] += 1 | |
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) | |
return sortedClassCount[0][0] # 返回出现次数最多的 | |
def createTree(dataSet,labels,labelProperty,depth,maxdepth): #这里也加了一些剪枝,限制了最大深度 | |
classList = [example[-1] for example in dataSet] | |
if classList.count(classList[0]) == len(classList): | |
return classList[0] | |
if len(dataSet[0]) == 1 or depth == maxdepth: | |
return majorityCnt(classList) | |
bestFeat,bestPartValue = chooseBestFeatureToSplit(dataSet,labelProperty) | |
if bestFeat == -1: | |
return majorityCnt(classList) | |
if labelProperty[bestFeat] == 0: | |
bestFeatLabel = labels[bestFeat] | |
myTree = {bestFeatLabel :{}} | |
labelsNew = copy.copy(labels) | |
labelPropertyNew = copy.copy(labelProperty) | |
del (labelsNew[bestFeat]) | |
del (labelPropertyNew[bestFeat]) | |
featValues = [example[bestFeat] for example in dataSet] | |
uniqueValue = set(featValues) | |
for value in uniqueValue: | |
subLabels = labelsNew[:] | |
subLabelsProperty = labelPropertyNew[:] | |
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels,subLabelsProperty,depth+1,maxdepth) | |
else: | |
bestFeatLabel = labels[bestFeat] + '<' + str(bestPartValue) | |
myTree = {bestFeatLabel:{}} | |
subLabels = labels[:] | |
subLabelProperty = labelProperty[:] | |
valueLeft = '1' | |
myTree[bestFeatLabel][valueLeft] = createTree(splitDataSet_c(dataSet,bestFeat,bestPartValue,'L'),subLabels,subLabelProperty,depth+1,maxdepth) | |
valueRight = '0' | |
myTree[bestFeatLabel][valueRight] = createTree(splitDataSet_c(dataSet,bestFeat,bestPartValue,'R'),subLabels,subLabelProperty,depth+1,maxdepth) | |
return myTree | |
def classify(inputTree,featLabels,featLabelProperty,testVec): | |
firstStr = list(inputTree.keys())[0] | |
firstLabel = firstStr | |
lessIndex = str(firstStr).find('<') | |
if lessIndex > -1: # 如果找到了小于号,说明这是个离散值处理 | |
firstLabel = str(firstStr)[:lessIndex] | |
secondDict = inputTree[firstStr] | |
featIndex = featLabels.index(firstLabel) | |
classLabel = None | |
for key in secondDict.keys(): | |
if featLabelProperty[featIndex] == 0: # 离散值 | |
if testVec[featIndex] == key: | |
if type(secondDict[key]).__name__ == 'dict': | |
classLabel = classify(secondDict[key],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict[key] | |
else: # 连续值 | |
partValue = float(str(firstStr)[lessIndex + 1:]) | |
if testVec[featIndex] < partValue: | |
if type(secondDict['1']).__name__ == 'dict': | |
classLabel = classify(secondDict['1'],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict['1'] | |
else: | |
if type(secondDict['0']).__name__ == 'dict': | |
classLabel = classify(secondDict['0'],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict['0'] | |
return classLabel |
# 4、预测准确率
labels,train,test,true = load_data() | |
labelProperty = [0,0,1,1,0] | |
Trees = createTree(train,labels,labelProperty) | |
predict = [] | |
for test_data in test: | |
result = classify(Trees,labels,labelProperty,test_data) | |
predict.append(result) | |
right = 0 | |
for i in range(len(predict)): | |
if predict[i] == true['Survived'][i]: | |
right += 1 | |
print(float(right)/float(len(predict))) |
最后的正确率为:,不高,不咋地,但是再仔细观察一下数据集,训练数据集和测试数据集里面男性极大部分都死了,女性极大部分都活下来了,所以只要一开始根据性别分类就可以极大提高正确率,也就是说这次数据并不能说明这个决策树的性能,所以进行一次后剪枝
def classify(inputTree,featLabels,featLabelProperty,testVec): | |
firstStr = list(inputTree.keys())[0] | |
firstLabel = firstStr | |
lessIndex = str(firstStr).find('<') | |
if lessIndex > -1: # 如果找到了小于号,说明这是个连续值处理 | |
firstLabel = str(firstStr)[:lessIndex] | |
secondDict = inputTree[firstStr] | |
featIndex = featLabels.index(firstLabel) | |
classLabel = None | |
for key in secondDict.keys(): | |
if featLabelProperty[featIndex] == 0: # 离散值 | |
if testVec[featIndex] == key: | |
if type(secondDict[key]).__name__ == 'dict': | |
classLabel = classify(secondDict[key],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict[key] | |
else: # 连续值 | |
partValue = float(str(firstStr)[lessIndex + 1:]) | |
if testVec[featIndex] < partValue: | |
if type(secondDict['1']).__name__ == 'dict': | |
classLabel = classify(secondDict['1'],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict['1'] | |
else: | |
if type(secondDict['0']).__name__ == 'dict': | |
classLabel = classify(secondDict['0'],featLabels,featLabelProperty,testVec) | |
else: | |
classLabel = secondDict['0'] | |
return classLabel | |
#测试决策树正确率 | |
def testing(myTree,data_test,labels,labelProperty): | |
error=0.0 | |
for i in range(len(data_test)): | |
if classify(myTree,labels,labelProperty,data_test[i])!=data_test[i][-1]: | |
error+=1 | |
#print 'myTree %d' %error | |
return float(error) | |
#测试投票节点正确率 | |
def testingMajor(major,data_test): | |
error=0.0 | |
for i in range(len(data_test)): | |
if major!=data_test[i][-1]: | |
error+=1 | |
#print 'major %d' %error | |
return float(error) | |
#后剪枝 | |
def postPruningTree(inputTree, dataSet, data_test, labels, labelProperties): | |
firstStr = list(inputTree.keys())[0] | |
secondDict = inputTree[firstStr] | |
classList = [example[-1] for example in dataSet] | |
featkey = copy.deepcopy(firstStr) | |
if '<' in firstStr: # 对连续的特征值,使用正则表达式获得特征标签和 value | |
featkey = re.compile("(.+<)").search(firstStr).group()[:-1] | |
featvalue = float(re.compile("(<.+)").search(firstStr).group()[1:]) | |
labelIndex = labels.index(featkey) | |
temp_labels = copy.deepcopy(labels) | |
temp_labelProperties = copy.deepcopy(labelProperties) | |
if labelProperties[labelIndex] == 0: # 离散特征 | |
del (labels[labelIndex]) | |
del (labelProperties[labelIndex]) | |
for key in secondDict.keys(): # 对每个分支 | |
if type(secondDict[key]).__name__ == 'dict': # 如果不是叶子节点 | |
if temp_labelProperties[labelIndex] == 0: # 离散的 | |
subDataSet = splitDataSet(dataSet, labelIndex, key) | |
subDataTest = splitDataSet(data_test, labelIndex, key) | |
else: | |
if key == '1': | |
subDataSet = splitDataSet_c(dataSet, labelIndex, featvalue,'L') | |
subDataTest = splitDataSet_c(data_test, labelIndex,featvalue, 'L') | |
else: | |
subDataSet = splitDataSet_c(dataSet, labelIndex, featvalue,'R') | |
subDataTest = splitDataSet_c(data_test, labelIndex,featvalue, 'R') | |
inputTree[firstStr][key] = postPruningTree(secondDict[key],subDataSet, subDataTest,copy.deepcopy(labels),copy.deepcopy(labelProperties)) | |
if testing(inputTree, data_test, temp_labels,temp_labelProperties) <= testingMajor(majorityCnt(classList),data_test): | |
return inputTree | |
return majorityCnt(classList) | |
def load_data(): | |
train=pd.read_csv('F:/机器学习/titanic/train.csv') | |
test=pd.read_csv('F:/机器学习/titanic/test.csv') | |
true=pd.read_csv('F:/机器学习/titanic/gender_submission.csv') | |
train_y = train['Survived'] | |
train.drop(["PassengerId","Ticket","Name","Cabin","Survived","Parch","SibSp"],axis=1,inplace=True) | |
test.drop(["PassengerId","Ticket","Name","Cabin","Parch","SibSp"],axis=1,inplace=True) | |
train["Sex"]=(train.Sex == "female").astype("int") | |
test["Sex"]=(test.Sex == "female").astype("int") | |
test_y = true['Survived'] | |
dict1 = {"S":0,"C":1,"Q":2} | |
train.Embarked = train.Embarked.map(dict1) | |
test.Embarked = test.Embarked.map(dict1) | |
train.Age = train.Age.fillna(train.Age.mean()) | |
test.Age = test.Age.fillna(test.Age.mean()) | |
train.Embarked = train.Embarked.fillna(train.Embarked.median()) | |
test.Embarked = test.Embarked.fillna(test.Embarked.median()) | |
train_dataset = [] | |
test_dataset = [] | |
labels = [x for x in train] | |
for i in range(len(train[labels[0]])): | |
one_case = [] | |
for j in labels: | |
one_case.append(train[j][i]) | |
one_case.append(train_y[i]) | |
train_dataset.append(one_case) | |
for i in range(len(test[labels[0]])): | |
one_case = [] | |
for j in labels: | |
one_case.append(test[j][i]) | |
one_case.append(test_y[i]) | |
test_dataset.append(one_case) | |
return labels,train_dataset,test_dataset,true |
labels,train,test,true = load_data() | |
labelProperty = [0,0,1,1,0] | |
t_labels = copy.deepcopy(labels) | |
t_labelProperty = copy.deepcopy(labelProperty) | |
Trees = createTree(train,labels,labelProperty,1,5) | |
Trees = postPruningTree(Trees,train,test,labels,labelProperty) | |
predict = [] | |
for test_data in test: | |
result = classify(Trees,t_labels,t_labelProperty,test_data) | |
predict.append(result) | |
right = 0 | |
for i in range(len(predict)): | |
if predict[i] == true['Survived'][i]: | |
right += 1 | |
print(float(right)/float(len(predict))) |
正确率达到了 93.54%,但根据 上的描述,这是用了一个假设的预测值,不是真正的测试答案,在 上提交了一下,正确率为, 还可以调参数,但我调不出来了
手写的决策树要画图有些困难,但还是可以画出来,代码如下:
# 获得叶子节点的数目 | |
def getNumLeafs(myTree): | |
numLeafs = 0 | |
firstStr = list(myTree.keys())[0] | |
secondDict = myTree[firstStr] | |
for key in secondDict.keys(): | |
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes | |
numLeafs += getNumLeafs(secondDict[key]) | |
else: numLeafs +=1 | |
return numLeafs | |
# 获得决策树的层数 | |
def getTreeDepth(myTree): | |
maxDepth = 0 | |
firstStr = list(myTree.keys())[0] | |
secondDict = myTree[firstStr] | |
for key in secondDict.keys(): | |
if type(secondDict[key]).__name__=='dict': # 查看是否为叶子节点 | |
thisDepth = 1 + getTreeDepth(secondDict[key]) | |
else: | |
thisDepth = 1 | |
if thisDepth > maxDepth: | |
maxDepth = thisDepth | |
return maxDepth | |
def plotNode(nodeTxt, centerPt, parentPt, nodeType): | |
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', | |
xytext=centerPt, textcoords='axes fraction', | |
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) | |
def plotMidText(cntrPt, parentPt, txtString): | |
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] | |
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] | |
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) | |
def plotTree(myTree, parentPt, nodeTxt): | |
numLeafs = getNumLeafs(myTree) # 决定整棵树的宽度 | |
depth = getTreeDepth(myTree) | |
firstStr = list(myTree.keys())[0] | |
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) | |
plotMidText(cntrPt, parentPt, nodeTxt) | |
plotNode(firstStr, cntrPt, parentPt, decisionNode) | |
secondDict = myTree[firstStr] | |
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD | |
for key in secondDict.keys(): | |
if type(secondDict[key]).__name__=='dict': #不是叶子节点 | |
plotTree(secondDict[key],cntrPt,str(key)) #递归 | |
else: #是叶子节点 | |
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW | |
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) | |
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) | |
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD | |
def createPlot(inTree): | |
fig = plt.figure(1, facecolor='white') | |
fig.clf() | |
axprops = dict(xticks=[], yticks=[]) | |
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) | |
plotTree.totalW = float(getNumLeafs(inTree)) | |
plotTree.totalD = float(getTreeDepth(inTree)) | |
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; | |
plotTree(inTree, (0.5,1.0), '') | |
plt.show() | |
decisionNode = dict(boxstyle="sawtooth", fc="0.8") | |
leafNode = dict(boxstyle="round4", fc="0.8") | |
arrow_args = dict(arrowstyle="<-") | |
createPlot(Trees) |
画出来的图如下:
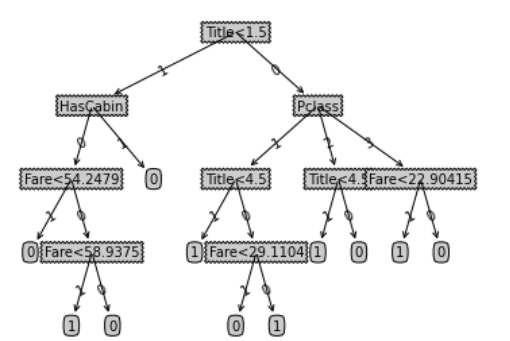
大工告成,完结撒花