# 指令流水线基本概念
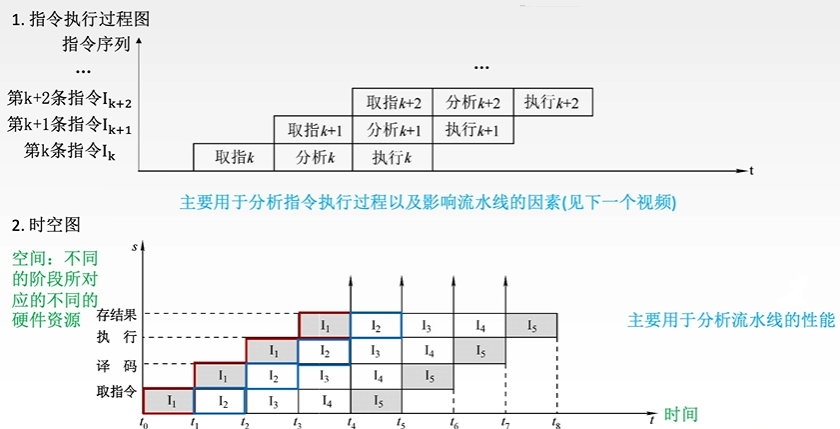
指令流水的定义:一条指令的执行过程可分成多个阶段 (或过程),根据计算机的不同,具体的分发也不同 (取指、分析、执行)
取指:根据 PC 内容访问主存储器,取出一条指令送到 IR 中
分析:对指令操作码进行译码,按照给定的寻址方式和地址字段中的内容形成操作数的有效地址 EA,并从有效地址 EA 中取出操作数
执行:根据操作码字段,完成指令规定的功能,即把运算结果写到通用寄存器或主存中
特点:每个阶段用到的硬件不一样
设取指、分析、执行 3 个阶段的时间都相等,用 t 表示,按一下几种方式分析 n 条指令的执行时间
- 顺序执行方式(传统冯诺依曼机采用顺序执行方式,又称串行执行方式)
- 总耗时:3nt
- 优点:控制简单,硬件代价小
- 缺点:指令执行速度较慢,在任何时候,处理机中只有一条指令在执行,各功能部件的利用率很低
- 一次重叠执行方式(第二条指令的取指阶段与上一条指令的执行阶段重合)
- 总耗时:(1+2n) t
- 优点:程序的执行时间缩短了 1/3,各功能部件的利用率明显提高
- 缺点:需要付出硬件上较大的开销代价,控制过程也比顺序执行复杂了
- 二次重叠执行方式(下一条指令在上一条指令分析阶段时就开始取指)
- 总耗时:(2+n) t
- 与顺序执行方式相比,指令的执行时间缩短近 2/3,这是一种理想的指令执行方式,在正常情况下,处理机中同时有 3 条指令在执行
注:也可以把每条指令分为 4 个或 5 个阶段,分成 5 个阶段是比较常见的做法
# 流水线的性能指标
吞吐率:吞吐率是指在单位时间内流水线所完成的任务数量,或是输出结果的数量
- 设任务数为 n,处理完成 n 个任务所用的时间为,则计算机流水线吞吐率 (TP) 的最基本公式为TP=\dfrac{n}
- 一条指令的执行分为 k 个阶段,每个阶段耗时,一般取 为一个时钟周期
- 当连续输入的任务 时,得最大吞吐率为TP_{max}=\frac{1}
- 理想状况下,,流水线的实际吞吐率为TP=\dfrac{n}
加速比:完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比
- 设 表示不使用流水线时的执行时间,即顺序执行所用的时间; 表示使用流水线时的执行时间
- 则计算流水线加速比 (S) 的基本公式为S=\frac{T_0}
- 单独完成一个任务耗时为,则顺序完成 n 个任务耗时
- 实际加速比为S=\dfrac{kn\Delta t}{(k+n-1)\Delta t}=\dfrac{kn}
- 当连续输入的任务 时,最大加速比为
效率:流水线的设备利用率称为流水线的效率
- 在时空图上,流水线的效率定义为完成 n 个任务占用的时空区有效面积与 n 个任务所用的时间与 k 个流水段所围成的时空区总面积之比
- 则流水线效率 (F) 的一般公式为E=\dfrac{T_0}
- :n 个任务占用时空区的有效面积
- :n 个任务占用的时间与 k' 个流水线所围成的时空区总面积
- 当连续输入的任务 时,最高效率
# 指令流水线影响因素
机器周期的设置:
各部件实际耗时:IF (100ns)、ID (80ns)、EX (70ns)、M (50ns)、WB (50ns)
为方便流水线的设计,将每个阶段的耗时取成一样,以最长耗时为准。即此处应将机器周期设置为 100ns
流水线每一个功能段部件后面都要有一个缓冲寄存器,或称为锁存器,其作用是保存本流水段的执行结果,提供给下一段流水使用
# 结构相关 (资源冲突)
由于多条指令在同一时刻争用同一资源而形成的冲突称为结构相关
解决办法:
- 后一相关指令暂停一周期
- 资源重复配置,数据存储器 + 指令存储器
# 数据相关 (数据冲突)
数据相关指在一个程序中,存在必须等前一条指令执行完才能执行后一条指令的情况,则这两条指令即为数据相关
解决办法:
- 把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行。可分为硬件阻塞 (stall) 和软件插入 "NOP" 两种方法
- 数据旁路技术。
- 编译优化:通过编译器调整指令顺序来解决数据相关
# 控制相关 (控制冲突)
当流水线遇到转移指令和其他改变 PC 值的指令而造成断流时,会引起控制相关
解决办法:
- 转移指令分支预测。简单预测 (永远猜 true 或 false)、动态预测 (根据历史情况动态调整)
- 预取转移成功和不成功这两个控制、流方向上的目标指令
- 加快和提前形成条件码
- 提高转移方向的猜准率
# 指令流水线的分类
- 部件功能级、处理机级和处理机间流水线
- 根据流水线使用的级别的不同,流水线可分为部件功能级流水线、处理机级流水线和处理机间流水线。
- 部件功能级流水就是将复杂的算数逻辑运算组成流水线工作方式。例如,可将浮点加法操作分为求阶差、对阶、尾数相加以及结果规格化等 4 个子过程
- 处理机级流水就是把一条指令解释过程分成多个子过程,如前面提到的取值、译码、执行、访存及写回 5 个子过程
- 处理机间流水是一种宏流水,其中给每一个处理机完成某一专门任务,各个处理机所得到的结果需存放在与下一个处理机所共享的存储器中。
- 单功能流水线和多功能流水线
- 按流水线可以完成的功能,流水线可分为单功能流水线和多功能流水线
- 单功能流水线指只能实现一种固定的专门功能的流水线
- 多功能流水线指通过各段间的不同连接方式可以同时或不同时地实现多种功能的流水线
- 动态流水线和静态流水线
- 按同一时间内各段之间的连接方式,流水线可分为静态流水线和动态流水线
- 静态流水线指在同一时间内,流水线的各段只能按同一种功能的连接方式工作
- 动态流水线指在同一时间内,当某些段正在实现某种运算时,另一些段却正在进行另一种运算。这样的对提高流水线的效率很有好处,但会使流水线控制变得很复杂
- 线性流水线和非线性流水线
- 按流水线的各个功能段之间是否有反馈信号,流水线可分为线性流水线和非线性流水线
- 线性流水线中,从输入到输出,每个功能段只允许经过一次,不存在反馈电路
- 非线性流水线中存在反馈电路,从输入到输出过程中,某些功能段将数次经过流水线,这种流水线适合进行线性递归计算
# 流水线的多发技术
- 超标量技术
- 每个时钟周期可并发多条独立指令
- 要配置多个功能部件
- 不能调整指令的执行顺序
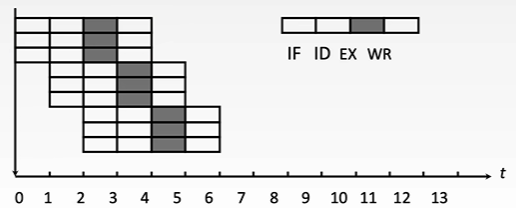
- 超流水技术
- 在一个时钟周期内再分段 (3 段)
- 在一个时钟周期内一个功能部件使用多次 (3 次)
- 不能调整指令的执行顺序
- 靠编译程序解决优化问题
- 流水线速度是原来速度的 3 倍

- 超长指令字
- 由编译程序挖掘出指令潜在的并行性
- 将多余能并行操作的指令组合成一条
- 具有多个操作码字段的超长指令字 (可达几百位)
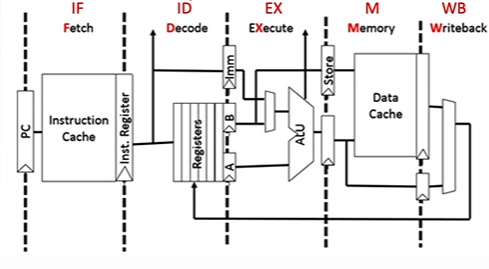
# 五段式指令流水线
①IF 取指 ->②ID 译码 & 取数 ->③EX 执行 ->④M 访存 ->⑤WB 写回寄存器
考试中常见的五类指令:
- 运算类指令、LOAD 指令、STORE 指令、条件转移指令、无条件转移指令
| 运算类指令举例 | 指令的汇编格式 | 功能 |
|---|---|---|
| 加法指令 (两个寄存器相加) | ADD Rs,Rd | (Rs)+(Rd)->Rd |
| 加法指令 (寄存器与立即数相加) | ADD #996,Rd | 996+(Rd)->Rd |
| 算数左移指令 | SHL Rd | (Rd)<<2->Rd |
注:Rs 指源操作数,Rd 指目的操作数
运算类指令
IF:根据 PC 从指令 Cache 取指令至 IF 段的锁存器
ID:取出操作数至 ID 段锁存器
EX:运算,将结果存入 EX 段锁存器
M:空段
LOAD 指令:
指令的汇编格式:LOAD Rd,996 (Rs) ;LOAD Rd,mem
功能:(996+(Rs))->Rd;(mem)->Rd
IF:根据 PC 从指令 Cache 取指令至 IF 段的锁存器
ID:将基址寄存器的值放到锁存器 A,将偏移量的值放到 Imm
EX:运算,得到有效地址
M:从数据 Cache 中取数并放入锁存器
WB:将取出的数写回寄存器
通常,RISC 处理器只有 "取数 LOAD" 和存数 "STORE" 指令才能访问主存
STORE 指令:
指令的汇编格式:STORE Rs,996 (Rd);STORE Rs,mem
功能:Rs->(996+(Rd));Rs->(mem)
IF:根据 PC 从指令 Cache 取指令至 IF 段的锁存器
ID:将基址寄存器的值放到锁存器 A,将偏移量的值放到 Imm。将要取的数存放到 B
EX:运算,得到有效地址。并将锁存器 B 的内容放到锁存器 Store
M:写入数据 Cache
WB:空段
条件转移指令:(转移类指令常采用相对寻址)
指令汇编格式:beq Rs,Rt,# 偏移量
功能:若 (Rs)==(Rt),则 (PC)+ 指令字长 +(偏移量 * 指令字长)->PC;否则 (PC)+ 指令字长 ->PC (注:通常在 IF 段结束之后 PC 就会自动 + 1)
指令汇编格式:bne Rs,Rt,# 偏移量
功能:若 (Rs)!=(Rt),则 (PC)+ 指令字长 +(偏移量 * 指令字长)->PC;否则 (PC)+ 指令字长 ->PC
IF:根据 PC 从指令 Cache 取指令至 IF 段的锁存器
ID:进行比较的两个数放入锁存器 A、B;偏移量放入 Imm
EX:运算,比较两个数
M:将目标 PC 值写回 PC
WB:空段
※很多教材把写回 PC 的功能段称为 "WrPC" 段,其耗时比 M 段更短,可安排在 M 段时间内完成
无条件转移指令:(转移类指令常采用相对寻址)
指令汇编格式:jmp #偏移量
功能:(PC)+ 指令字长 +(偏移量 * 指令字长)->PC
IF:根据 PC 从指令 Cache 取指令至 IF 段的锁存器
ID:偏移量放入 Imm
EX:将目标 PC 值写回 PC
M:空段
WB:空段
"WrPC 段" 耗时比 EX 段更短,可安排在 EX 段时间内完成。WrPC 段越早完成,就越能避免控制冲突。当然,也有的地方会在 WB 段时间内才修改 PC 值
例题:
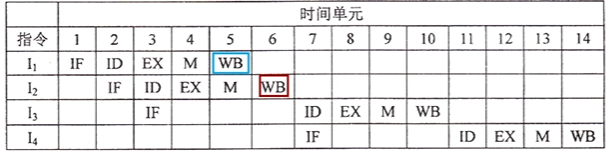
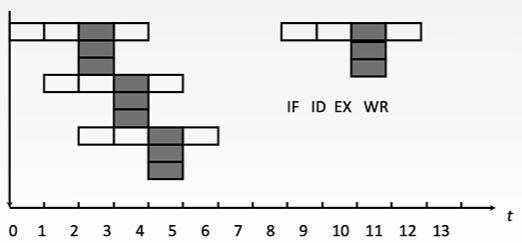
I3 的 ID 段和 I4 的 IF 段被阻塞的原因各是什么?
- I3 与 I1 和 I2 存在数据相关,取数指令必须在 WB 段后数据才会被存到寄存器中,而加法指令 ID 段是需要取出数据的,因此被推迟
- I4 的 IF 段必须在 I3 进入 ID 段后才能开始,否则会覆盖 IF 段锁存器的内容。只有上一条指令进入 ID 段后,下一条指令才能开始 IF 段,否则会覆盖 IF 段锁存器的内容